Data Security rules have changed in the age of Big Data. The V-Force (Volume, Veracity and Variety) has changed the landscape for data processing and storage in many organizations. Organizations are collecting, analyzing, and making decisions based on analysis of massive amounts of data sets from various sources: web logs, click stream data and social media content to gain better insights about their customers. Their business and security in this process is becoming increasingly more important. IBM estimates that 90 percent of the data that now exists have been created in the past two years.
A recent study conducted by Ponemon Institute LLC in May 2013 showed that average number of breached records was 23,647. German and US companies had the most costly data breaches ($199 and $188 per record, respectively). These countries also experienced the highest total cost (US at $5.4 million and Germany at $4.8 million). On average, Australian and US companies had data breaches that resulted in the greatest number of exposed or compromised records (34,249 and 28,765 records, respectively).
A Forrester report, the “Future of Data Security and Privacy: Controlling Big Data”, observes that security professionals apply most controls at the very edges of the network. However, if attackers penetrate your perimeter, they will have full and unrestricted access to your big data. The report recommends placing controls as close as possible to the data store and the data itself, in order to create a more effective line of defense. Thus, if the priority is data security, then the cluster must be highly secured against attacks.
According to ISACA’s white paper – Privacy and Big Data published in August 2013, enterprises must ask and answer 16 important questions, including these key five questions, which, if ignored, expose the enterprise to greater risk and damage:
- Can the company trust its sources of Big Data?
- What information is the company collecting without exposing the enterprise to legal and regulatory battles?
- How will the company protect its sources, processes and decisions from theft and corruption?
- What policies are in place to ensure that employees keep stakeholder information confidential during and after employment?
- What actions are company taking that creates trends that can be exploited by its rivals?
Hadoop, like many open source technologies such as UNIX and TCP/IP, wasn’t originally built with the enterprise in mind, let alone enterprise security. Hadoop’s original purpose was to manage publicly available information such as Web links, and it was designed to format large amounts of unstructured data within a distributed computing environment, specifically Google’s. It was not written to support hardened security, compliance, encryption, policy enablement and risk management.
Here are some specific steps you can take to secure your Big Data:
- Use Kerberos authentication for validating inter-service communicate and to validate application requests for MapReduce (MR) and similar functions.
- Use file/OS layer encryption to protect data at rest, ensure administrators or other applications cannot gain direct access to files, and prevent leaked information from exposure. File encryption protects against two attacker techniques for circumventing application security controls. Encryption protects data if malicious users or administrators gain access to data nodes and directly inspect files, and renders stolen files or copied disk images unreadable
- Use key/certificate management to store your encryption keys safely and separately from the data you’re trying to protect.
- Use Automation tools like Chef and Puppet to help you validate nodes during deployment and stay on top of: patching, application configuration, updating the Hadoop stack, collecting trusted machine images, certificates and platform discrepancies.
- Create/ use log transactions, anomalies, and administrative activity to validate usage and provide forensic system logs.
- Use SSL or TLS network security to authenticate and ensure privacy of communications between nodes, name servers, and applications. Implement secure communication between nodes, and between nodes and applications. This requires an SSL/TLS implementation that actually protects all network communications rather than just a subset.
- Anonymize data to remove all data that can be uniquely tied to an individual. Although this technique can protect some personal identification, hence privacy, you need to be really careful about the amount of information you strip out.
- Use Tokenization technique to protect sensitive data by replacing it with random tokens or alias values that mean nothing to someone who gains unauthorized access to this data.
- Leverage the Cloud database controls where access controls are built into the database to protect the whole database.
- Use OS Hardening – the operating system on which the data is processed to harden and lock down data. The four main protection focus areas should be: users, permissions, services, logging.
- Use In-Line Remediation to update configuration, restrict applications and devices, restrict network access in response to non-compliance.
- Use the Knox Gateway (“Gateway” or “Knox”) that provides a single point of authentication and access for Apache Hadoop services in a cluster. The goal is to simplify Hadoop security for both users (i.e. who access the cluster data and execute jobs) and operators (i.e. who control access and manage the cluster).
A study conducted by Voltage Security showed 76% of senior-level IT and security respondents are concerned about the inability to secure data across big data initiatives. The study further showed that more than half (56%) admitted that these security concerns have kept them from starting or finishing cloud or big data projects. The built-in Apache Hadoop security still has significant gaps for enterprise to leverage them as-is and to address them, multiple vendors of Hadoop distributions: Cloudera, Hortonworks, IBM and others have bolstered security in a few powerful ways.
Cloudera’s Hadoop Distribution now offers Sentry, a new role-based security access control project that will enable companies to set rules for data access down to the level of servers, databases, tables, views and even portions of underlying files.
Its new support for role-based authorization, fine-grained authorization, and multi-tenant administration allows Hadoop operators to:
- Store more sensitive data in Hadoop,
- Give more end-users access to that data in Hadoop,
- Create new use cases for Hadoop,
- Enable multi-user applications, and
- Comply with regulations (e.g., SOX, PCI, HIPAA, EAL3)
RSA NetWitness and HP ArcSight ESM now serve as weapons against advanced persistent threats that can’t be stopped by traditional defenses such as firewalls or antivirus systems.
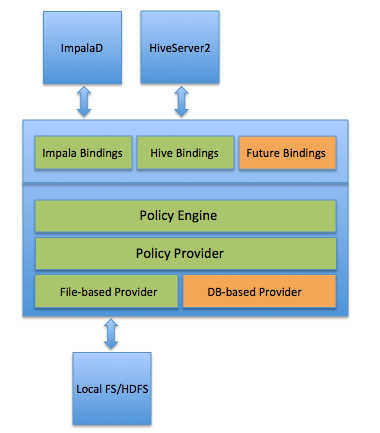
Figure 1: Cloudera Sentry Architecture
Hortonworks partner Voltage Security offers data protection solutions that protect data from any source in any format, before it enters Hadoop. Using Voltage Format-Preserving Encryption™ (FPE), structured, semi-structured or unstructured data can be encrypted at source and protected throughout the data life cycle, wherever it resides and however it is used. Protection travels with the data, eliminating security gaps in transmission into and out of Hadoop and other environments. FPE enables data de-identification to provide access to sensitive data while maintaining privacy and confidentiality for certain data fields such as social security numbers that need a degree of privacy while remaining in a format useful for analytics.

Figure 2: Hortonworks Security Architecture
IBM’s BigInsights provides built-in features that can be configured during the installation process. Authorization is supported in BigInsights by defining roles. InfoSphere BigInsights provides four options for authentication: No Authentication, Flat File authentication, LDAP authentication and PAM authentication. In addition, the BigInsights installer provides the option to configure HTTPS to potentially provide more security when a user connects to the BigInsights web console.
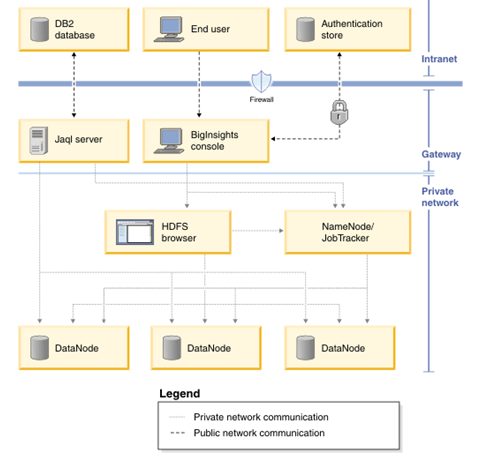
Figure 3: IBM BigInsights Security Architecture
Intel, one of the latest entrants to the distribution-vendor category — came out with a wish list for Hadoop security under the name Project Rhino
First of all, although today the focus is on technology and technical security issues around big data — and they are important — big data security is not just a technical challenge. Many other domains are also involved, such as legal, privacy, operations, and staffing. Not all big data is created equal, and depending on the data security requirements and risk appetite/profile of an organization, different security controls for big data are required.





You must be logged in to post a comment.